Je reprend l’exemple d’un fichier texte contenant une multitude d’identifiants.
Des identifiants qui commencent par 4 chiffres puis 2 lettres (exemple: 1502KQ) respecte le standard voulu, les autres non.
Nous souhaitons donc isoler les identifiants ne correspondant pas à ce standard.
Pour cela, crée un fichier, test.txt par exemple, et on y inscrit cette liste d’identifiants:
7737OM
8053HR
8184MH
8579MX
9254NF
1034AP
ADMIN01
ADMIN26
BIZOT
4569DF
BOURGAINET
CHACONNI
4126NR
4685ET
D?ALES
5016NW
DESOUSASSE06
FITGERERT
FRANCINETTE
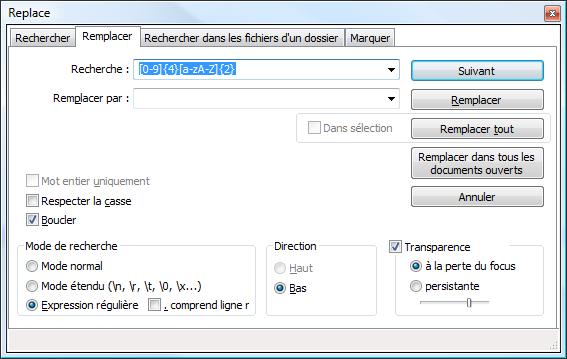
Pour afficher les occurrences qui correspondent à notre expression régulière, [0-9]{4}[a-zA-Z]{2} (pour 4 chiffres et 2 lettres en minuscule ou majuscule):
egrep "[0-9]{4}[a-zA-Z]{2}" test.txt
7737OM
8053HR
8184MH
8579MX
9254NF
1034AP
4569DF
4126NR
4685ET
5016NW
Pour afficher au contraire les occurrences qui correspondent pas à notre expression régulière, on rajoute l’option « -v »:
egrep -v "[0-9]{4}[a-zA-Z]{2}" test.txt
ADMIN01
ADMIN26
BIZOT
BOURGAINET
CHACONNI
D?ALES
DESOUSASSE06
FITGERERT
FRANCINETTE
Note: On peut également utiliser grep avec l’option « -E » qui forcer grep à se comporter comme egrep:
grep -E "[0-9]{4}[a-zA-Z]{2}" test.txt
Autres exemples:
Recherche les mots dont b n’est pas suivi de o:
egrep "b[^o]" test.txt
Recherche toute ligne qui commence par « De: », « Sujet: » ou « Date: »:
egrep "^(De|Sujet|Date):" test.txt
Recherche et affiche chaque ligne du fichier test.txt qui contient l’occurence bonjour ou Bonjour, les numéros de ligne sont également affichés (option -n):
egrep -n "[bB]onjour" test.txt
Liste toute les lignes du fichier test.txt commençant avec le caractère $:
egrep "^\\$" test.txt
Liste tous les fichiers et répertoires dans le répertoire courant qui ne se terminent pas avec .txt:
ls -l | egrep "[^.txt]$"
Liste tous les fichiers et répertoires dans le répertoire courant qui se terminent avec .txt:
ls -l | egrep "[.txt]$"
Affiche uniquement les lignes dont le numéro de téléphone commence par un 1:
egrep "^1" test.txt
Recherche les lignes avec un 2 à la seconde position et n’importe quel caractère en première position:
egrep "^.2" test.txt
Recherche les lignes dont le premier caractère est différent de 1:
egrep "^[^1]" test.txt