Voici une petite astuce qui permet d’obtenir la liste des liens symboliques contenus dans un répertoire:
ls -F | grep @$ | awk -F@ '{print $1}'
La même chose mais cette fois de façon récursive:
find . -type l
Voici une petite astuce qui permet d’obtenir la liste des liens symboliques contenus dans un répertoire:
ls -F | grep @$ | awk -F@ '{print $1}'
La même chose mais cette fois de façon récursive:
find . -type l
Du texte délimité par des guillemets est une pratique assez courante lorsque l’on pratique la ligne de commande, en particulier lorsqu’ils traitent avec des fichiers qui ont des espaces dans les noms.
Mais comment savoir si il faut utiliser des guillemets simples ou doubles? Jetons un petit coup d’œil à la différence entre les deux, et dans quel cas utiliser l’un ou l’autre.
La règle générale est que les guillemets doubles permettent la lecture des variables dans les citations, et des guillemets simples ne le font pas. Continue de lire.
Citations avec un texte simple
Si il faut juste traiter quelques mots de texte, il n’y a pas vraiment d’importance sur celle que vous utilisez, car le résultat sera le même.
Par exemple, ces deux commandes vont créer toutes les deux un répertoire nommé « Test 1 »:
mkdir "Test 1"
mkdir 'Test 1'
A noter que vous pouvez également utiliser mkdir Test \ 1 si vous le vouliez.
La différence entre guillemets simples et doubles arrivent lorsque vous avez affaire à des variables.
Premièrement, nous allons assigner la variable:
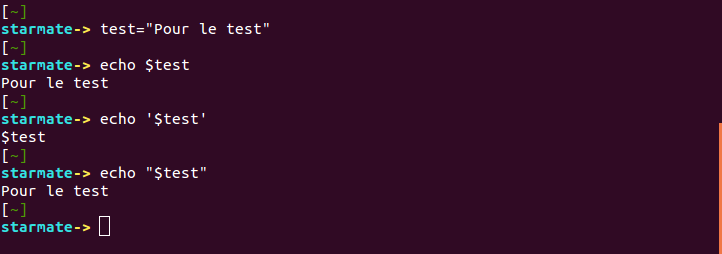
test="Pour le test"
Maintenant, vous pouvez utiliser cette variable sur la ligne de commande, comme ceci, qui devrait tout simplement afficher Pour le test sur la console:
echo $test
La différence entre guillemets doubles et simples devient plus clair lorsque vous utilisez des guillemets simples. Par exemple, si vous exécutez la commande suivante:
echo '$test'
Vous ne verrez pas la valeur de la variable s’afficher, mais ‘$test « . Cela est dû aux guillemets simples, il faudra donc que utiliser des guillemets doubles.
La même chose fonctionne lorsque vous utilisez le caractère ` dans une commande.
Par exemple, imaginons que vous vouliez utiliser la commande pwd à l’intérieur d’une autre commande:
echo `pwd`/test
Si vous étiez dans mon dossier personnel, vous verriez sortie qui ressemblait à ceci:
/home/starmate/test
Imaginons maintenant, que vous créez un dossier qui a un espace dans son nom, et que vous voulez utiliser la commande ln pour faire un lien symbolique dans votre répertoire personnel pointant dessus.
Généralement, on a besoin de spécifier le chemin complet lors de l’utilisation de ln, il est donc beaucoup plus facile à utiliser `pwd`.
Vous ce qui passe lorsque l’on utilise ln sans l’encadrer par des doubles guillemets:
ln –s `pwd`/test /home/starmate/lien1

Au lieu de cela, vous aurez besoin d’entourer de guillemets:
ln –s "`pwd`/test" /home/starmate/lien1
Pour un exemple plus concret, supposons que nous avons plusieurs fichiers comme dans cet exemple, où tous les noms de fichiers ont des espaces en eux:
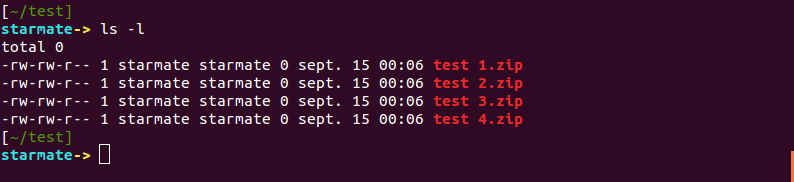
La commande unzip ne supporte pas l’utilisation du signe étoile (*) pour prendre tous les fichiers.
Vous aurez besoin d’utiliser une boucle « for » à la place. C’est là où les choses deviennent intéressantes:
for f in *.zip;do unzip $f;done
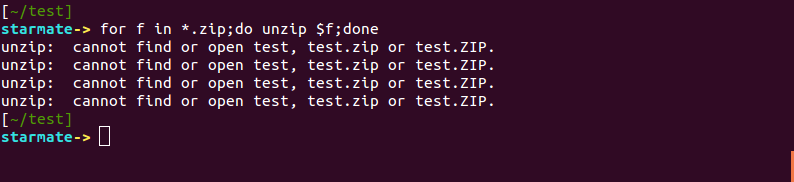
Put*1#! On dirait que cela n’a pas fonctionné.
A la place il faut utiliser des guillemets autour de la variable $f, comme ceci:
for f in *.zip;do unzip "$f";done
Maintenant, chaque fois la commande la boucle for s’exécute, elle va se créer une commande comme celle-ci:
unzip "test 1.zip"
Maintenant que nous avons passé en revue les exemples, nous allons juste rapidement en revue au cas où vous l’avez manqué:
Guillemets doubles
Guillemets simples
Ainsi se termine la leçon sur les guillemets.
A chaque nouvelle mise à jour de packages dell-openmanage sur linux, la sonde nagios check-openmanage ne fonctionne plus, cela est dû à la présence de sémaphores.
Pour résoudre le problème:
chkconfig dsm_sa_ipmi on
service nrpe stop
for i in `ipcs -a | grep -i nagios | awk '{print $2}'`; do ipcrm -s $i; done
for i in dsm_om_shrsvc dsm_om_connsvc dataeng dsm_sa_ipmi; do service $i
stop; done
for i in dsm_sa_ipmi dataeng dsm_om_connsvc dsm_om_shrsvc; do service $i
start; done
service nrpe start
FirewallD est un service qui permet de mettre en place une gestion dynamique du pare-feu sous RedHat, CentOS et Fedora.
Il s’appuie sur l’infrastructure Netfilter.
Les règles gérées par le service FireWallD sont appliquées san savoir besoin de redémarrer le parefeu.
Les règles existantes, toujours utiles, restent donc en place. Et les modules noyaux complémentaires utilisés ne sont pas déchargés.
La seule contraintes concernant FirewallD est qu’il nécessite que l’ensemble des règles de filtrage soient appliquées par lui même de façon à ce que son état (règles en cours) reste synchronisé avec celui du noyau.
Installation:
yum -y install firewalld
Démarrage:
systemctl start firewall
Voici quelques notes pour pouvoir se servir de l’interface du pare-feu sur votre CentOS, Fedora ou RHEL. Les règles ne sont pas prises en tant réel, mais lors du rechargement des règles.
Pour connaître l’activation du pare-feu:
firewall-cmd --state
Pour connaître la « zone » par défaut:
firewall-cmd --get-active-zones
Regarder les règles existantes sur la zone par defaut :
firewall-cmd –get-default-zone
Pour lister les règles de la zone « public »:
firewall-cmd --zone=public --list-all
Ajouter http (TCP/80) dynamiquement:
firewall-cmd –add-service http
ou
firewall-cmd --zone=public --add-service=http
Ajouter http (TCP/80) pour une prise en compte au redémarrage:
firewall-cmd –permanent –add-service http
ou
firewall-cmd --permanent --zone=public --add-service=http
Pour ajouter un port de manière permanente (ici 80 sur tcp):
firewall-cmd --permanent --zone=public --add-port=80/tcp
Pour supprimer un port de manière permanente (ici 80 sur tcp):
firewall-cmd --permanent --zone=public --remove-port=80/tcp
Pour recharger les règles du pare-feu:
firewall-cmd --reload
ou
systemctl restart firewalld.service
Plus d’info ici.
Le Pipe » | « :
Le symbole pipe » | » permet de passer le résultat d’une commande a la suivante.
Exemple:
commande1 | commande2
Plus grand que » > « :
Le symbole > redirige le résultat de la commande vers un fichier.
Si le fichier existe déjà, son contenu sera effacé.
Exemple:
commande > fichier
Deux fois plus grand que » >> « :
Redirige le résultat de la commande vers un fichier.
Si le fichier existe déjà, le résultat de la commande est ajouté à la suite du fichier.
Exemple:
commande >> fichier
Plus petit que » < « :
Exemple:
commande < fichier
Pour l’entrée standard, la sortie standard et la sortie d’erreur le numéro identifiant sera respectivement 0, 1 et 2.
Ces identifiants vont nous permettre de faire des redirections plus évolués.
Si l’identifiant source n’est pas précisé, c’est la valeur 1 qui sera prise par défaut (1>&2 peut s’écrire alors >&2).
Rediriger la sortie standard dans un fichier:
1> fichier.txt
qui s’écrit aussi comme ça (1 par défaut):
> fichier.txt
Rediriger la sortie d’erreur dans un fichier:
2> fichier.txt
Rediriger la sortie standard sur la sortie d’erreur:
1>&2
qui s’écrit aussi comme ça (1 par défaut):
>&2
1 étant l’identifiant descripteur source et 2 l’identifiant du descripteur sur lequel on veut rediriger.
Rediriger la sortie d’erreur sur la sortie standard:
2>&1
2 étant l’identifiant descripteur source et 1 l’identifiant du descripteur sur lequel on veut rediriger.
Rediriger la sortie standard et la sortie d’erreur dans un fichier:
> fichier.txt 2>&1
qui s’écrit aussi comme ça:
1>>fichier.txt2>>fichier.txt
ou comme ça (1 par défaut):
>>fichier.txt2>>fichier.txt
Le fichier /dev/null est un peu particulier.
Si on affiche son contenu on n’obtient rien, et si on écrit quelque chose dedans ça disparaît.
Cela est très pratique pour supprimer une sortie.
Pour rediriger la sortie standard vers /dev/null :
> /dev/null
Pour rediriger toutes les sorties vers /dev/null :
> /dev/null 2>&1